論文まとめ: Are You Sure You Want to Use MMAP in Your Database Management System?
研究室内に向けまとめたものの転載です.
一言でいうと
著者/所属機関
Andrew Crotty $^1$ , Viktor Leis $^2$ , Andrew Pavlo $^1$
$^1$ Carnegie Mellon University $^2$ University of Erlangen-Nuremberg
mmap(memory-mapped I/O)について
mmapはメモリに用いるアドレス空間を,I/Oデバイス(HDDやSSDはこれに含まれる)と共有して, I/Oデバイスに対するRead/Writeをメモリに対するRead/Writeと同一に見えるようにする仕組み.
「プログラマーのためのCPU入門」の7章が参考になると思います.
概要
- mmapを使えば,まるでファイル全体がメモリに乗っているように見える.
- これでバッファプールの実装が不要になったかのように思えたが,すぐには顕在化しない一貫性や性能への悪影響があった.
- 実際,最初mmapを採用していたDBMSも,後に自力でI/Oを管理するように舵を切っている.
Disk-based DBMSとページ管理
- 実際に積んでいるメモリのサイズより多くのデータを扱うlarger-than-memoryはDisk-based DBMSにおいて重要
- メモリよりも大きいデータを扱うために,二次記憶(HDDやSSD)とメモリ間でデータを出し入れしつつ頑張る.
- いわゆる"ページング"
- メモリが足りなければ,今乗っているページがevictされて,新しいページを読み込む
- ページの大きさは大抵の場合4KiB
- ちなみに,Linuxならめちゃくちゃデカい(1桁MiBぐらい)ページを確保できる("superpages")
- mmap無しの場合,ページの管理はシステムコール(read,write)経由で完全にDBMSが行う
- 一方,mmapを使えばページ管理の責務をOSに転嫁できる
- DBMSから見るとすべてのデータがメモリ上にあるように見える
- 当然,実装はものすごく楽になる
- 性能面からも,明示的システムコールがなくなる上に,OSのページキャッシュを使えるので早くなるように思われた
- 有名なDBMSも過去にmmapを使っていて,なんなら mmapのおかげで早い! と謳うものすらあった.
mmapについて
mmapを利用したときの流れ
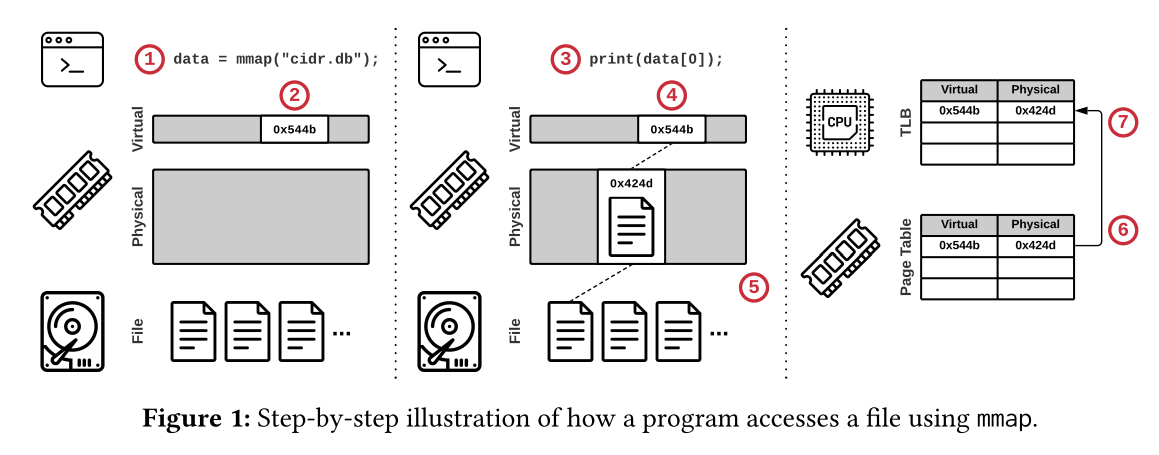
以下はmmapを使ったときの動き
別のページが要求されれば同様の手順を踏む
- ページフォールトが起きてページキャッシュがいっぱいな場合,OSはページをevictする
- evict時にはページテーブルとTLBの両方からアドレスの対応を消す
- evictを走らせるコアのTLBだけでなく,リモートのコアのTLBからも消さないといけない
- 現代のCPUには,よそのコアのTLBとの一貫性を保証する機能はないので,OSが割り込みで解決する
- これを"TLB shootdown"という
- これがヤバい!(実験結果を参照)
- これを"TLB shootdown"という
- 現代のCPUには,よそのコアのTLBとの一貫性を保証する機能はないので,OSが割り込みで解決する
ケーススタディ
MongoDB
- MongoDBは最初(納期に追われて)mmapを利用して作られたが,2つの問題に直面した
- 1つは一貫性を保証するための手続きが複雑になったこと(後で詳しく)
- もう1つは二次記憶にあるデータの圧縮ができないこと
- マッピングされているので,メモリ上のデータレイアウトが二次記憶のものと一致しなければならないことによる
- 圧縮すればI/Oの回数が減る上に,容量も削減できるのに……
- 2019年に完全にmmapを使わなくなった
- ただし,2020年に限定的な用途のためにmmapが復活している
InfluxDB
- 数GBの時点で(恐らくpage evictionの影響で)I/Oがスパイクすることが判明
- しかもコンテナ環境などで使えないことも分かった
- 2020年にコアを書き換えてmmapは消滅
SingleStore
その他
- Google製のLevelDBのreadのボトルネックがmmapのせいだったので,FacebookがforkしてRocksDBを作った
- TileDBの論文では,SSDにおいてmmapがreadシステムコールより高コストなことが示されている
- 「SSDはアクセスがミリ秒未満だから」とのこと
- ScyllaDBはI/Oの代替を色々と検討した結果,mmapではpage eviction戦略もI/O操作のスケジューリングも細かくできないので使わなかった
- その他,色々……
mmapで起きる問題
問題1: Transactional Safety
- OSはいつでもdirty pageをフラッシュしていい
- もちろん,コミットされていないトランザクションの途中でも……
- これの対策は3つ
- OS copy-on-write
- user space copy-on-write
- shadow paging
OS copy-on-write
- 昔のMongoDBが使っていた
- データベースファイルのコピーを2つ用意する手法
- 1つはプライマリ,もう1つはステージング用
- ステージング用のファイルを使ってトランザクションによる更新を処理し,それをプライマリに反映という手続き
- ステージング用のファイルはcopy-on-write方式でページを管理する
- この手法は2つの問題がある
- 1つは並行するトランザクションの読み取り時にコミットされた最新のデータがプライマリに反映されていることを保証しなければならないこと
- このために更新をペンディングしなければならない
- もう1つはcopy-on-writeといえども,更新の度にステージング用コピーの容量が増えていくこと
- 最終的にdbファイル2つ持ってるみたいなことに
mremapという命令で一応解消できるが,mremapの前後で更新の喪失を防ぐためにはやはりコストがかかる
User Space Copy-on-Write
- SQLite,MonetDB,RavenDBが使っている
- User spaceでバッファを用意して,そこに変更を積んでいき,DBMS管理で適宜mmapされたメモリに転送する手法
- (個人的には,これ普通にバッファ管理してるだけじゃない?と思います)
shadow paging
- LMDBが使っている
- DBファイルのコピーを2つ用意し,片方をプライマリ,もう片方をshadowとする手法
- 書き込み時には,必要なページをプライマリからshadowへコピーして,shadowへ変更を適用
- その後
msync命令で二次記憶へ転送し,shadowが新しいプライマリとしてふるまう- もとのプライマリはshadowとして振る舞う
- 簡単そうに見えるけど,partial writeを見ないことを保証しないといけないのが鬼門になる
- LMDBではsingle writerで解決
- (絶対性能出ないだろこれ)
- LMDBではsingle writerで解決
問題2: I/O Stalls
- バッファプールを使う場合,非同期I/Oを使って,クエリ処理中に必要なページを読んでおくテクがある
- B+木のスキャンが典型的なユースケース
- しかし,mmapは非同期読み取りをサポートしていない
- I/Oのコストを隠蔽できない!
- evictのコントロールができないので,いかなるページへのアクセスもページフォールトを起こしてI/Oで詰まる可能性がある
- システムコールを駆使すれば一応解決は可能
- ①
mlockを使って特定ページのevictを防ぐ- ただし,
mlockしすぎるとメモリが足りなくなる - unlockに気をつける必要もある
- ただし,
- ②
mapadviseを使って,アクセスパターンのヒントをOSに渡し,プリフェッチを狙う- OSはヒントを無視していいので意味ないかも
- 間違ったヒントを渡すと悲惨(実験結果を参照)
- ③プリフェッチ用のスレッドを走らせる
- ①
- これらの解決策でどうにかはなるけど,めちゃくちゃ複雑になる
- mmapを使う目的は取り扱いの簡単さだったはずなのに……
問題3: エラーハンドリング
- データが壊れてないことを保証するのもDBMSの役割
- よってデータの破損を検知するためにチェックサムを取るDBがある
- メモリ安全性が弱い言語を使ったとき,ポインタまわりのエラーでメモリに乗っているページの中身が破損する場合がある
- バッファプールを使えば永続化する前に検知して止められるが,mmapを使うと破損したデータが自動的に永続化される
- mmapが絡んだメモリは
SIGBUSを引き起こす可能性があり,これはシグナルハンドラ経由で解決しなければならない- バッファプールなら単一モジュールでI/Oエラーを捌けるのに……
問題4: パフォーマンス
- バッファプールなら単一モジュールでI/Oエラーを捌けるのに……
- 一貫性などの問題は実装次第でなんとかなるけど,パフォーマンスは手の付けようがない
- そもそもmmapの利点として考えられていたのは以下の3つ
- read/writeなどのシステムコールが少ない
- OSのpage cacheに乗っているページへのポインタを返すことができ,バッファへの余計なコピーが不要
- データをuser spaceにコピーしなくていいので省メモリ
- 以上の点はI/Oデバイスの帯域が広がるほど効くはず
- しかし,page evictionのせいでスケールしないことが分かった
- ボトルネックは以下の3つ
- ページテーブルの同期による競合
- シングルスレッドで走るpage eviction
- TLB shootdown
実験
実験設定
- 使用機器は以下
- read-onlyワークロード
- 一貫性のためのコピーがいらないので,mmapに有利
- ランダムリードとシーケンシャルスキャンでそれぞれ検証
- ベースラインはfioというI/O用ベンチマークツールとDirect I/Oを合わせたらしい
- よくわかりません
- DBのサイズは2TB
実験結果
ランダムリード
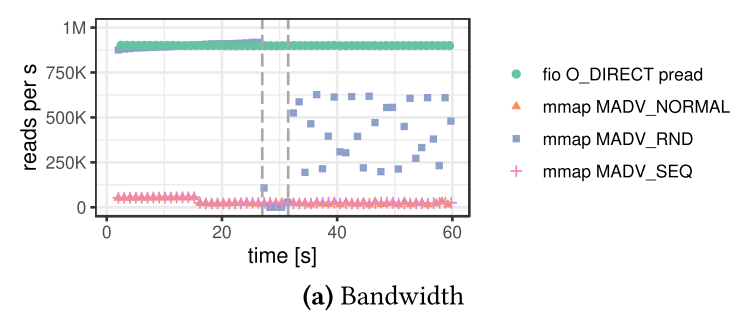
- Figure 2aは100スレッドでランダムリードしたときのスループット
- MADV_NORMALは特に特別なことをしないパターン(アクセスパターンのヒントを与えないのと同じ)
- 他は名前の通り
- ベースラインは900k reads
- NVMe SSDのレイテンシ的に,これは理論値
- mmapの方はおしまい
- ランダムリードのヒントを渡したものは27秒までは耐えている
- 5秒ぐらい地を這ったのち,fioの半分ぐらいの性能に
- 27秒辺りでページキャッシュが埋まり切った
- 間違ったヒントを渡したものは悲惨な結果に
- ランダムリードのヒントを渡したものは27秒までは耐えている
- ページキャッシュが小さい(100GB << 2TB)ので95%のアクセスがページフォールトを起こしている
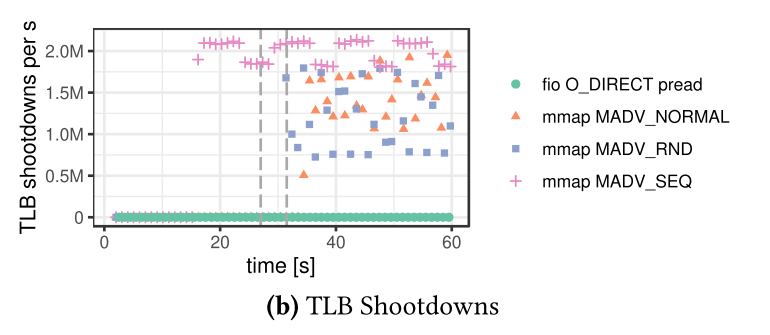
- ランダムリード中のTLB shootdownの数を
/proc/interruptを使って計測- ご覧の有り様
シーケンシャルスキャン
- ご覧の有り様
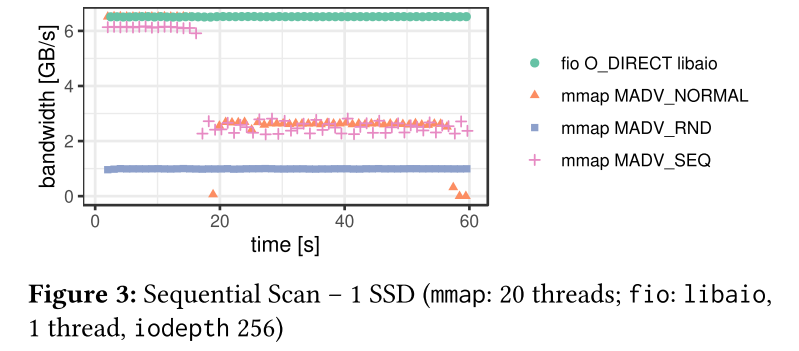
- Figure 3は1つのSSDを使ってシーケンシャルスキャンをした時のスループット
- fioは帯域を使い切れている
- mmapの方はおしまい
- ランダムリード同様,キャッシュが埋まるまでは耐えるが急に沈む
- 間違ったヒントを渡したらやはり悲惨
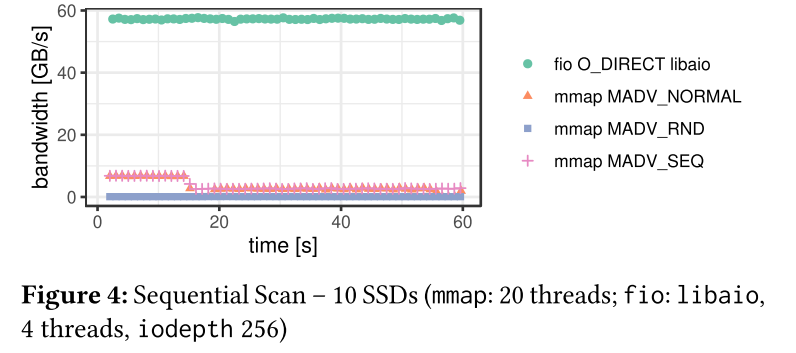
- Figure 4は同様の実験をRAID-0構成の10個のSSDを使ってシーケンシャルスキャンをした時のスループット
- fioはざっくり10倍ぐらいに(RAID-0なので)
- mmapはどれもSSD 1台構成の時と同じ性能になっている
- つまり,mmapはSSDが1台で,ページキャッシュが埋まっていない間だけfioに匹敵する
- 裏を返せば,それ以外は……
まとめ
mmapを使わない方がいい人
mmapを使ってもいいかも?な人
- 走らせたいワークロードがメモリに乗る人
- (ならインメモリDBでいいじゃん)
- データの一貫性とか技術的負債とか考えられないぐらい納期が迫っている人
- そんな奴はいない
コメント
- LMDBへの熱いdisを感じてイイですね.
- 2019年にIEEEが出してる雑誌のLMDBの紹介記事によると,LMDBは世界で最も高速かつ効率的で,最も安全な組み込みデータストアの1つらしいです. そうなんだ.
2022年の振り返りと2023年の目標
今年こそ,今年こそ頑張ります.今年こそは.
2022年の振り返り
まず,昨年の目標を振り返っていきます. 2022年の目標は以下の通りでした.
それぞれ,達成できたかどうかも含めて振り返っていきます.
研究室配属: 〇
研究室配属バトルは無事に勝利でき,名古屋大学のデータベース研究室に配属されました. DB研は編入試験の時からずっと希望していたところなので,入れてよかったです.
同級生とのつながりが一切なかったので競合相手のGPAが一切分からず,配属決定日はかなりドキドキしていました. 勝ちが決まった時はちょっと叫びました.
内定: ×
「どうせ落ちるだろうけど学部卒枠で一度就活を経験しておいて,その経験を2年後の就活に活かすのアリだな」と思って,一社だけ選考を受けてみました. 受からないことが前提の人生設計でしたが,受かったら院に行かずにその企業に行くつもりでした. あんまり対策はやってなかった1ので,普通に最終面接で落ちました.受かりたいなら対策をしましょう.
面接後に落選を確信しましたが,それでも不合格通知を見たときはちょっと落ち込みました. 就活ってしんどいね……
積読消化: ×
昨年本腰を入れて読んだ本は詳説データベースの後半だけ. 全然ダメですね. そもそも自分には読書の習慣がない(漫画すらほとんど読まない)ので,そこから始めないと.
院試合格: 〇
受かりました.試験が終わった瞬間に秋採用のスケジュールを調べ始めるぐらいには壊滅でしたが,なぜか受かっていました. 出来レースを疑いましたが,ちゃんと試験の成績がいい順に取っていくらしいです.なんで受かったんだろう.
DBスペシャリスト: ×
午後1の勉強を1秒もしていなかったため,午後1で破滅しました.
TOEFL 80点: ×
受けてすらないです. そもそもこの目標は海外で暮らしたい!と思って2,まずは留学から始めてみようとしていたから出てきたものです. しかし,冷静に考えてみると優れた治安と安くて美味しいご飯を捨てるのはあり得ないという結論に至り,海外計画はやめることにしました. よって,TOEFLは受けませんでした.今年も受けません.
2023年の目標
今年の目標は以下の通りです.
- 学部を卒業する
- IPSJ全国大会で学生奨励賞を取る
- kindでKubernetesに触ってみようシリーズを完結までもっていく
- 研究室MTGで分散DBのハンズオンをやりたい
- 積読を消化する
- リーダブルコード
- Kubernetes完全ガイド 第2版
- 暗号技術入門 第3版
- 達人に学ぶSQL徹底指南書 第2版
- パタヘネ下 第5版
- エリック・エヴァンスのドメイン駆動設計
- etc...
- DBスペシャリストにリベンジ(午前1免除が今年までなので)
- Rust入門
- BSTとか,もっと頑張ってB+Treeとかが書けると良い
- 論文を30本読む
- 索引系と分散系を狙いたい
- talent-planのtiny-kvをやってみる
- ストレージエンジン自作に着手する(一年たらずで完成は無理でしょうけれども……)
- 来年3月のDEIMで発表できるようにする
- M2で国際会議に出られるぐらい進捗を出したい
- TOEIC 900点以上(来年8月の院試用)
- 研究室の人と話すときに緊張しないようになる
- 積読を消化しないうちから本を買わない
思いついたらどんどん追記していきます
一年後に,このリストを見ながら〇×をつけていくのが楽しみです.それではまた来年!
【備忘録】kindでKubernetesに触ってみよう③
前回のあらすじ
ついにnginxを起動してブラウザからアクセスすることに成功しました。
nginxを走らせるPodを立ち上げ、そのPodの80番ポートをServiceのNodePortを使ってホストマシンの特定のポートに公開することで動いています。
マニフェストはこんな書き方もできるよ
前回のservice.yamlとnginx.yamlを例にとると
# service.yaml apiVersion: v1 kind: Service metadata: name: hello-service spec: type: NodePort selector: app: nginx ports: - port: 80 nodePort: 30001 protocol: TCP --- apiVersion: v1 kind: Pod metadata: name: nginx labels: app: nginx spec: containers: - name: nginx image: nginx:latest
このように、---で区切れば一つのファイルで複数のリソースを記述できます。
これをapplyすると
$ kubectl apply -f=service.yaml service/hello-service created pod/nginx created
こんな感じになって、二つ作れていることがわかります。今後は積極的にこういう書き方をしていきます。
ReplicaSetとDeployment
前回、「ReplicaSetはPodを冗長化して管理するもの、DeploymentはReplicaSetを管理するもの」といいました。もうちょっとマシな説明をしていきます。
ReplicaSet
名前から明らかですが、ReplicaSetの本質はレプリケーションです。
ReplicaSetは指定したPodのレプリカを指定した数だけ作ってくれるリソースです。ただ作るだけでなく、作った後はレプリカ数を一定に保つように監視していて、Podが死んだら回復させてくれます(オートヒーリング)。ちなみに、Nodeが死んだ場合にも、別のNode上でPodを走らせることで、トータルのレプリカ数を維持します。
ReplicaSetのおかげで、指定したレプリカ数だけPodが動いていることが保証されるわけですね。
昔はReplicationControllerという名前だったらしいです。公式ドキュメントを見るとdeprecatedの匂いが充満していますね。Kubernetesに歴史あり。
Deployment
DeploymentはReplicaSetを管理しますが、ReplicasetとPodの関係とはまた違います。
マサカリを恐れずに言うと、DeploymentはReplicaSetのアップデートを管理する機能です。もっというと、"ローリング"アップデートを上手いことやってくれます。
通常のアップデート(Red/Black Deployを想定)はアップデートしたいReplicaSetのバージョンを一気に全部切り替えるのに対し、ローリングアップデートでは、古いバージョンのReplicaSet(旧RS)から新しいバージョンのReplicaSet(新RS)へ、少しずつ移行していきます(アップデート完了時に旧RSのレプリカ数は0になります)。
例えば、(Deploymentを使わずに)ReplicaSetを作ったとしましょう。少し時間が経ち、アプリケーションの新しいバージョンができたので、ReplicaSetをアップデートすることになりました。ここで、新RSを作ってServiceの実行を新RSに全振りすると問題が発生したときにまずいことになります。すなわち、不幸にも本番環境でエラーが起きた場合には、サービスが完全にダウンすることになります。
一方、リクエストを少しずつ新RSに流していくようにした場合はどうでしょう。こちらでは、新RSでサービスが崩壊したとしても旧RSは生きているので、アップデートの影響でサービス全体が完全に停止することはありません。"アップデートのためのメンテナンス"というダウンタイムも消えます。
また、新RSが使い物にならないことがわかるとアップデートは即刻中止されますが、この時にすることは"ロールバック"ですよね。実はこちらもDeploymentの仕事のうちであり、Kubernetesの機能を使って旧RS時代へ戻すことができます。
PodとReplicaSetとDeployment、どれを使えばいいのか
先ほどまでの説明から、DeploymentはReplicaSetを管理していて、ReplicaSetはPodを管理しているといえます。よって、我々は常に最上位のオブジェクトであるDeploymentを使えばOKです。例外はきっとあるけど!
前回も言いましたが、公式ドキュメントでも大抵の場合Deploymentを使うことが推奨されています。
Cluster, Deployment, Serviceの立ち上げ
Clusterのマニフェストはこちら。
# cluster.yaml kind: Cluster apiVersion: kind.x-k8s.io/v1alpha4 name: hpa nodes: - role: control-plane - role: worker extraPortMappings: - containerPort: 30001 hostPort: 8000
前回と名前が違うだけですが一応載せておきました。
続いて、Deployment, Serviceのマニフェストがこちら。
# deploy.yaml apiVersion: apps/v1 kind: Deployment metadata: name: hpa-deploy labels: app: nginx spec: replicas: 1 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx resources: limits: cpu: 500m requests: cpu: 200m --- apiVersion: v1 kind: Service metadata: name: hpa-svc spec: type: NodePort selector: app: nginx ports: - port: 80 nodePort: 30001
長い記述ですが分解していけば何をやっているかは簡単です(難しいとぼくもわからない)。
とりあえずNodePortについては名前以外前回と同じであることがわかると思います。
Deploymentについてですが、templete:以下を見ると、一旦resources:という新キャラを見なかったことにすると、前回のPodのマニフェストで全く同じ記述がありましたね。templeteはレプリケーションしたいPodのspecificationを書いている場所になります。
resources:ですが、ここにはPodが要求する計算資源の量が書いてあります。CPUの場合、1000mを指定すればCPU1コア分の計算資源が割り当てられます。ちなみに、1m単位で指定できます。今回は要求量が200mで上限が500mということになります。メモリも指定できますが割愛!
次に、ネストが浅い方のspec:以下に注目すると、replicas: 1やtemplete:を従えていることから、これはReplicaSetのspecificationであることがなんとなくわかります。Deploymentのspecificationを記述しているspec:がないのは、Deploymentはアップデート時の挙動以外はReplicaSetと等価なので、ReplicaSetのspecがあれば十分だからですね(実は等価じゃないかもしれんけどちょっと触った程度の僕には、アップデート以外の部分でのReplicaSetとDeploymentの違いはわかりませんでした。ごめんね!)。
以上から、このDeploymentはnginxを積んだコンテナ1個(レプリカ数が1だから)を起動して、そいつの80番ポートとホストマシンの8000番ポートを繋げることを意味していることがわかります。
$ kind create cluster --config=cluster.yaml $ kubectl apply -f deploy.yaml
で早速起動しましょう。
Horizontal Pod Autoscaler(HPA)でオートスケーリングをしてみよう
HPAとは
HPAはDeployment、ReplicaSet、StatefulSet(まだ未登場)といった、k8sがレプリケーションしてくれるやつのレプリカ数を、CPU使用率などのメトリクスを使って自動で増減してくれるリソースです。水平にスケールするからHorizontal。
Horizontalがあるなら当然Vertical Pod Autoscalerもある(自動でPodに割り当てる計算資源を変えてくれる)のですがこちらはあんまり使われていないような気がします。
HPAが使うメトリクスですが、Kubernetesが自動でいい感じに監視してくれていると思いきや、そうでもないです。k8sではMetrics APIを通してコンテナのCPU使用率などを見られるのですが、このAPIはプラグインによって実装されるらしく、公式ではメトリクスサーバがないとMetrics APIは利用できないと明記されています。
というわけでクラスタにメトリクスサーバを立てましょう。
Metrics Serverを立てよう
Metrics Serverは、コンテナを監視しているkubeletのSummary APIから統計情報を得て、それをkube-api-serverからアクセスできるようにしてくれる人です。この人をクラスタに召喚すればMetrics APIが使えるようになり、kubectl top nodesとかのtop系が動くようになります。
ちなみに、Metrics Serverはメトリクスの精度が重要な場合には適していなくて、あくまでHPA(とVPA)のために使うものだそうです。
さて、リポジトリのREADMEのInstallationに従い、以下のコマンドを実行しましょう。
$ kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml serviceaccount/metrics-server created clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created clusterrole.rbac.authorization.k8s.io/system:metrics-server created rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created service/metrics-server created deployment.apps/metrics-server created apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
これで、クラスタにMetrics Serverをインストールできました
……と思いきや、kubectl top nodesはまだ動きません。
$ kubectl top nodes Error from server (ServiceUnavailable): the server is currently unable to handle the request (get nodes.metrics.k8s.io)
Metrics ServerのPodを確認してみると、
$ kubectl get po -A NAMESPACE NAME READY STATUS RESTARTS AGE ... kube-system metrics-server-847dcc659d-mrldn 0/1 Running 0 96s ...
Metrics ServerのPodが一向にReadyにならないことがわかります。
調べてみたところ、 kindのIssueのコメントに解決策がありました。
kubectl edit deploy metrics-server -n kube-system
で、argsの部分に、- --kubelet-insecure-tlsを追加すると、
kubectl get po -A NAMESPACE NAME READY STATUS RESTARTS AGE ... kube-system metrics-server-5c85b4d56f-8m5bk 1/1 Running 0 56s ...
無事Readyになりました。topを動かしてみると
kubectl top nodes NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% hpa-control-plane 629m 7% 710Mi 2% hpa-worker 130m 1% 225Mi 0%
OK!
ちなみに、minikubeならアドオン入れるだけでOKという簡単仕様らしいので、Metrics Serverが必要ならminikubeでやってもいいかも。
HPAリソースの立ち上げ
HPAリソースもマニフェストを書いて立ち上げることはできるのですが、公式のQuick Start的なやつにコマンドで立ち上げるやつが載っているので、今回はそれを使います。というわけで以下を実行。
$ kubectl autoscale deployment hpa-deploy --cpu-percent=50 --min=1 --max=10 horizontalpodautoscaler.autoscaling/hpa-deploy autoscaled
さて、ちゃんと作ったdeploymentがhpaできるようになっているかを確認しましょう。
$ kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE hpa-deploy Deployment/hpa-deploy <unknown>/50% 1 10 1 26s
作ってすぐはメトリクスの情報が届いてないので、unknownになります。 しばらくすると、
$ kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE hpa-deploy Deployment/hpa-deploy 0%/50% 1 10 1 18m
こんな感じで、リソースの使用率が見えます。AGEの値が無駄にデカいですが、別に18分待たないといけないわけではなく、デフォルトでは30秒間隔でメトリクスを取得するらしいです。だからといって30秒待てば動くわけではないですが。
ServiceにDoSアタックを仕掛けよう
HPAが立ち上がったので、DoSアタックでCPU使用率を爆上げさせれば、レプリカ数が増えることが期待されます!というわけでabコマンドでDoSアタックを仕掛けましょう!
デフォルトでは入ってないので、お持ちでない方は次のコマンドをどうぞ。
$ sudo apt install apache2-utils
それでは、次のコマンドでDoSアタックが始まります。nやcはPCのスペックに合わせて適当に弄ってください.
$ ab -n 100000 -c 10 http://localhost:8000/
30秒ほど待ってHPAリソースの様子を見てみると
$ kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE hpa-deploy Deployment/hpa-deploy 207%/50% 1 10 1 48m
CPU使用率が爆上がりしています。 続けて、もうちょっとだけ待ってから再び見てみると
$ kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE hpa-deploy Deployment/hpa-deploy 207%/50% 1 10 4 48m
レプリカ数が増えてますね!オートスケールができていることがわかります。ちなみに、最終的にレプリカ数は6まで増えました。
さて、レプリカ数が減らないうちに、もう一度同じ条件でabコマンドを実行して、処理速度の違いを確認してみましょう。
1回目(最初はレプリカ数1)の結果は以下
$ ab -n 100000 -c 10 http://localhost:8000/ ... Time taken for tests: 61.301 seconds ... Requests per second: 1631.30 [#/sec] (mean) ...
2回目(最初からレプリカ数6)の結果は以下
$ ab -n 100000 -c 10 http://localhost:8000/ ... Time taken for tests: 46.180 seconds ... Requests per second: 2165.45 [#/sec] (mean) ...
トータルでかかった時間が15秒減り、1秒当たりに捌くリクエストが500件ほど増えていますね!HPAの力は偉大💪
お気持ち
ReplicaSetのユースケースに、アップデートされないReplicaSetはDeploymentによる管理が不要みたいに書いてたけど、別にDeploymentで管理してもいいと思う。
となると、ReplicaSetはユーザ独自の戦略でアップデートしたいときのみ、直接使われるということになるはず。しかし、外部のプラグインを使うとカナリーリリースとかもできるらしいので、結局ReplicaSetが直接使われることはないんじゃないか。
お片付け
$ kind delete cluster --name=hpa
次回予告
- Persistent VolumeとかStatefulSetをやる
- fluentdとか立ち上げてDaemonSetも一緒にやるかも?
これにておしまい。
【備忘録】kindでKubernetesに触ってみよう②
前回のあらすじ
$ kind create cluster
で無のクラスタができました。
$ kubectl cluster-info
でcontrol planeのAPI server(後述)のポートを見つけて、無謀にもcurlでリクエストを出し、無事門前払いされました。
クラスタ生成時に自動生成されるPodを眺めてみよう
$ kind create cluster
を行ったとき、バックヤードではKubernetesクラスタの司令塔であるところのコントロールプレーンが作成されています。コントロールプレーンがないとクラスタは動きません。 ちなみにクラウド環境だとコントロールプレーンはプロバイダが提供してくれるらしいです。
コントロールプレーンには、クラスタを管理するための4つのPodが積まれています。次のコマンドで確認可能です。
$ kubectl get pods --all-namespaces | grep kind-control-plane
結果は以下
kube-system etcd-kind-control-plane 1/1 Running 0 9m57s kube-system kube-apiserver-kind-control-plane 1/1 Running 0 9m59s kube-system kube-controller-manager-kind-control-plane 1/1 Running 0 9m57s kube-system kube-scheduler-kind-control-plane 1/1 Running 0 9m57s
etcd、kube-apiserver、kube-controller-manager、kube-schedulerの4つですね、
etcdはKey Value Storeであり、クラスタに関する情報が保存されています。
kube-apiserverは、kubectl applyとかのクラスタをいじるためのKubernetesのAPIを外部に公開している人です。kubectlコマンドは全てここへと通じます。認証されてないユーザがクラスタをいじれるとまずいのでここにブラウザで殴り込みをかけると当然ながら、無慈悲な弾かれが発生します(1敗)。RBACという方式でアクセス制御しているらしいです。
kube-controller-managerは、Nodeが死んだときの対応や、Podが死んだときのオートヒーリングの実行など、多くの役割があります。
kube-schedulerは、Podを走らせるNodeを決める役割があります。決め方はリソース要求量とか、各種制約とか、いろいろな指標が考慮されるようです。
といった話は全てこちらの公式ドキュメントに書いてありますので、一読してみてください。別にエキスパートでもなんでもない謎の人間のブログより公式ドキュメント、これ鉄則。
さて、この記事の存在価値を全否定したところで、今回はNginxを立ち上げてトップページを確認するところまで行きます。
Nginxを立ち上げよう
の前に
Pod、Service、Nodeに関して言及したいと思います。
PodはKubernetesで動かしたいプロセス(大抵はアプリケーション)を実際に実行してくれるやつです。つまり、こいつがすべての基本になります。 その中身は1つ以上のコンテナであり、メインのコンテナと、それを補佐するサブのコンテナ(Envoyみたいなプロキシとか、fluentdみたいなログエージェントとか)から成ります。サブのコンテナをサイドカーと言います。
Serviceは、公式ドキュメントによると
Podの集合で実行されているアプリケーションをネットワークサービスとして公開する抽象的な方法です。
らしいです。
こいつはアプリケーションをクラスタの外に公開したり、クラスタ内でアプリケーション同士が協調するためのお膳立てをしたりしてくれます。すなわちアプリケーションにエンドポイント(仮想IP)を与えて通信を成立させるわけですね。しかもそのエンドポイントはクラスタ内で勝手に動いているDNSに登録されるようになっています。kubectl cluster-infoで見える謎のDNSくんはServiceのためのコンポーネントだったんですね。
クラウド環境だとクラウドプロバイダが提供するロードバランサをServiceとして使えるらしいですが、手元で遊んでるだけの僕は関係ないのでパスします。MetalLB?アハハ!
Nodeですがこれは一番簡単で、Podが走るマシンのことです。仮想マシンでも物理マシンでもどっちでもOKですが、今回のケースでは仮想マシンですね。
ところで、ここを逃すとおそらく書く機会がないので言及しますが、実はすべてのノード(マスターノード、ワーカーノード)上で動いている人たちがいます、kubeletはコンテナが動いているか監視してくれます。kube-proxyはNode内のネットワークをいい感じにしてくれて、この人のおかげでPodへの(クラスタ内/外両方からの)アクセスが実現している(=Serviceという抽象的な機能の一部を担当している)ようです。
コンテナの実行を担当するコンテナランタイムくんはちょっと前に話題になりましたね。Kubernetes 1.20からコンテナランタイムにDockerを使うのが非推奨に、1.24に至っては完全に使えなくなりました。現在は主にcontainerdが使われていまして、それを確認することもできます。適当にクラスタを立ち上げて
kubectl describe node | grep Container
を打つと
Container Runtime Version: containerd://1.5.10
このとおりわかります。
クラスタの設定
kindではマルチノードなクラスタを立てることができます。せっかくなので、マスターノードとワーカーノードを別で立ててみましょう。 クラスタのマニフェストは以下のようになります。
# cluster.yaml kind: Cluster apiVersion: kind.x-k8s.io/v1alpha4 name: hello-world #クラスタ名 nodes: - role: control-plane - role: worker extraPortMappings: - containerPort: 30001 #ServiceでNodePortとして開放するポート hostPort: 8000 #ホスト向けに公開するポート protocol: TCP
extraPortMappingsに関して、containerPort/hostPortはServiceとホストを繋げるための設定です。このケースでは30001番で動いているServiceをホストの8000番につなげます。 apiVersionは何も考えず写経しました。こいつだけは何をもって決めるのか一切わかりません。あとは見たまんまですね。nodesのroleを増やせばNodeが増えます。
kind create cluster -f cluster.yaml
でクラスタを立ち上げられます。この時点では、このクラスタは無です(まぁコントロールプレーンには4つのPodがありますが……)。
Podの設定
今回のようにちょろっとNginxを走らせたいというだけであれば、Podの中身はnginxのコンテナ1つだけで事足ります(ただし、例えばログをきっちり管理したい場合、ログ基盤に転送するためのサイドカーをつけたりするはず)。 というわけでPodのマニフェストは以下のようになります。
# nginx.yaml apiVersion: v1 kind: Pod metadata: name: nginx #Pod名 labels: app: nginx #key,valueともに何でもよい。Serviceのselectorフィールドで再び登場する。 spec: containers: - name: nginx image: nginx:latest
ラベルは、Kubernetesのオブジェクトを選択するために使います。今回はServiceが公開するPod(∈オブジェクト)を選択するのに使います。本番環境用のPodを選択したい場合、env:prdみたいなキーをつけると選択するときに便利そうですね。まぁ実務経験ないから知らんけど。
specにはPodの中身、つまりコンテナ(と永続化が必要な場合はボリューム)の情報が記述されます。
というわけで、上述のマニフェストを使ってnginx用のPodをワーカーノードに生やしてあげましょう。そのためのコマンドがkubectl applyです。
$ kubectl apply -f nginx.yaml pod/nginx created
これでnginxが走るPodを起動できました。最後に、このPodをクラスタの外部(=ホストの8000番)に公開するための設定をすればクリアです。 (ちなみに、PodをPod単体で起動するとオートヒーリングが効かないので、次回紹介するReplicaSetやDeployment、というか大抵Deploymentのみを使うことが推奨されます。ざっくりいうとReplicaSetはPodを冗長化して管理するもの、DeploymentはReplicaSetを管理するものです。)
Serviceの設定
Serviceのマニフェストはこちらです。
#service.yaml apiVersion: v1 kind: Service metadata: name: hello-service #service名 spec: type: NodePort selector: app: nginx # 公開したいpodのラベル(pod用のmanifestで設定したlabelのKeyとValueが一致するもの) ports: - port: 80 #内部で使うポート nodePort: 30001 #クラスタの外からアクセスするときに使うポート protocol: TCP
ここでselectorとしてさっきのPodにつけたラベルのapp:nginxが出てきましたね。これはapp:nginxのラベルがついているPod全体の集合を並列に展開されたサービスとみなしてその窓口になる仮想IPを作って負荷分散するというものでしょう(TODO:これが嘘か本当か調べる)。これ全然違うPodでラベルが重複したらヤバいことになりそうですね。
portに関しては、ここでは省略しているフィールドが関連していて、説明しづらいので一旦パスです。
ところで、僕はこの記事を書いていてnodePortに関して強烈な違和感を覚えました。
クラスタの外からアクセスするための仕組みがそもそもあるなら、クラスタのマニフェストで謎のマッピングなんかせずにこれを使ってアクセスすればいいじゃないですか。
NodePortの使い方は<任意のNodeのIP>:<NodePort>って書いてました。どのNodeに出してもクラスタ内で適切に回してくれるみたいですね。その代わり、異なる二つのNodeで同じポート番号を別の用途に使おう!ということはできないようです。それができる嬉しさは特に思いつかないですが。
さて、NodeのIPを確認するには
kubectl describe node
でOKです。結果は
... Addresses: InternalIP: 172.21.0.2 Hostname: hello-world-worker ...
_人人人人人人人人人人人_
> Internal IPしかない <
 ̄Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^ ̄
Internal IPしかないということはNodeが外部に公開されていないということで、つまりNodePortによるクラスタ外からのアクセスは不可能ということです。
怒りのあまりk8sのリポジトリにissueを2億個ぐらい立ててやろうかと思いましたが、すんでのところでNodeに関する公式ドキュメントを読みました。
これらのフィールドの使い方は、お使いのクラウドプロバイダーやベアメタルの設定内容によって異なります。
ウー
追記1 kindのLoadBalancerのページに
With Docker on Linux, you can send traffic directly to the loadbalancer's external IP if the IP space is within the docker IP space.
On macOS and Windows, docker does not expose the docker network to the host. Because of this limitation, containers (including kind nodes) are only reachable from the host via port-forwards, ...(以下略)
って書いてました。特定OS上のDockerの挙動からくる問題みたいですね。WindowsやMacを使うときは覚えておくといいかも。
ドンマイ。
気を取り直してserviceを起動しましょう。
$ kubectl apply -f service.yaml service/hello-service created
これでやることは全て終わったので、localhost:8000へアクセスすると。Nginxのいつものアレが見られるはずです。
ダメだった場合、コピペをミスったか、この記事が古すぎてKubernetesが別時空の存在になってしまったか、環境構築が失敗していると思います。
とりあえずkubectl get podsやkubectl get svcやkubectl get eventで怪しげなエラーが起きていないか見てみましょう。
お気持ち
これホストにNodePort繋げてるNodeが沈んだら終わりじゃね?
お片付け
kind delete cluster --name=hello-world
次回予告
- ReplicaSetとDeploymentやる
- HPAもやる
これにておしまい。
【備忘録】kindでKubernetesに触ってみよう①
最近、一年も積んでいた「Kubernetes完全ガイド 第二版」をようやく読み始めました。
そんなわけで、この本を読んでKubernetesを完全に理解したいと思い、とりあえず手を動かすことを決意しました。
以下、(バージョンによる違いがなければ)手順と結果の再現性はあると思いますが、解説的なアレはないです。知識がないからね。備忘録備忘録。
使用したOSするWindows 10です。 WinでローカルにKubernetesを立てるなら、minikubeかDocker Desktop for Windowsの付属のアレかkindか 自力 ですが、今回はkindを使うことにします。(minikubeは以前ハンズオンで触ったことがあるし、Dockerの付属のやつはできることしょぼいらしいので)
インストール
今回インストールするもの
インストール手順
cd your_workspace mkdir -p tmp/bin curl -LO "https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl" curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.12.0/kind-linux-amd64 mv ./kind ./kubectl tmp/bin export PATH=$(pwd)+"/tmp/bin:$PATH"
DockerとWSL2は、ググってよしなにやってください(こんなの見てる時点でこの2つは既に入れてるだろうと思っている)
また、Docker Desktop for Windowsを入れたら勝手にWSL2でkubectlが入ってきますが、こいつは使いません。
$ kubectl version --client $ kind version
を実行して
$ kubectl version --client
Client Version: version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.6", GitCommit:"ad3338546da947756e8a88aa6822e9c11e7eac22", GitTreeState:"clean", BuildDate:"2022-04-14T08:49:13Z", GoVersion:"go1.17.9", Compiler:"gc", Platform:"linux/amd64"}
$ kind version
kind v0.12.0 go1.17.8 linux/amd64
ちゃんとバージョンが出てきたらとりあえずOKです(バージョンを気にする必要があるようなことは当面の間しないはず!)。
Kubernetesクラスタの立ち上げ
$ kind create cluster
を実行して、しばらく待つと
Creating cluster "kind" ... ✓ Ensuring node image (kindest/node:v1.23.4) ✓ Preparing nodes ✓ Writing configuration ✓ Starting control-plane ✓ Installing CNI ✓ Installing StorageClass Set kubectl context to "kind-kind" You can now use your cluster with: kubectl cluster-info --context kind-kind Have a question, bug, or feature request? Let us know! https://kind.sigs.k8s.io/#community
このとおり、立ち上がります。
特にDockerイメージを指定していなければ、デフォルトでkindest/nodeというイメージを使ったノード一つからなるクラスタが立ち上がります。
僕は、とりあえずcurlで叩いてみる人間なので、
$ kubectl cluster-info
で、ポート(多分ランダム)を確認しまして、
Kubernetes control plane is running at https://127.0.0.1:44921 CoreDNS is running at https://127.0.0.1:44921/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
アクセスをすると……!
$ curl localhost:44921
Client sent an HTTP request to an HTTPS server.
グエー
どうやら、現状このクラスタは外部からのアクセスを受け付けるものではないようで、httpsに直したリクエストを出しても認証できなくて死ぬ。おとなしくNginxでも立ち上げてくださいという感じなのかな?
とはいえ、動いていることは確認できたので、お片付け。
kind delete cluster
これにておしまい。
はてなリモートインターン2021に参加しました :saikounonatsu:
はてなインターン2021参加しました
TL;DR
いや、全部読んでください。
前半戦(講義パート)
講義では企画からインフラまで、Web開発に必要なものを洗いざらい教わった。(カリキュラムはこちら)
とんでもない物量の講義が毎日襲いかかってきて、これが最前線のWeb企業の速度か……と内心ビビっていた。
しかし、受講者がそう思うということは、用意した側はたぶん5倍以上の苦労があったはず。我々8人のインターン生に教えるためにそれだけのリソースを割いてくれているわけで、こんな教育が充実したインターンは他にないのではないかと思う(ほかのインターン行ったことないけど)。
講義では特に個人ではなかなか腰を据えて勉強するに至れないKubernetesやマイクロサービス、食わず嫌いだったデザイン、爆速でJS→TS→Reactと駆け抜けていくフロントエンドなどが印象に残っている(特にフロントエンドはボリュームがすごいを通り越して 異常 の域に至っていると思う、本当にすごい講義&資料だった)。全ての講義が大変ためになるので、これらを受けられたというだけでも、このインターンは今後の人生にきわめて大きな好影響を与えてくれると確信できる。Webエンジニアを目指す全人類にはてなインターンを経験して欲しい。
ちなみに、2019年のインターン生である id:lunastera さんが今年にはすでに講師を担当されており、後進の育ち具合に戦慄した。
前半戦2(課題パート)
ブログにmd記法を導入したりとか、URLからのタイトルフェッチをするServiceを立てるとかそういった課題があった。多分2020年の課題と同じだと思う。
適切な質問ができなかったり、そもそもgRPCとKubernetesの理解がだいぶ浅かったりで、特に見せ場なく終了した。
テストの更新漏れがあってCIが落ちまくったり、課題がクリアできなかったりしたので、これは前半で脱落するやつか〜〜〜???と思ったが、全然杞憂だった。破滅しても割と大丈夫です、安心してください。
後半戦(業務パート)
希望していたブクマチームに配属してもらえて最高だった!
何をどれぐらい書いていいのかの判断ができないので、詳細は全然語らないが、インターンの真価はこの業務パートにあったと自信を持って言える。
学生のうちから、ユーザが大勢いるサービスのかなり重要な機能に携わる経験ができて本当に良かった。ただ言われた通りにコードを書くだけではなく、レビューやテストをすり抜けたバグをちょこちょこ見つけたり、UX的な部分に自分の意見を取り入れてもらったりもしていて、拙いなりにもチームの一部として動けていた感覚があったし、機能への愛着もめちゃくちゃ湧いている。自分の子供感ある。
実装した機能はこちら👇
bookmark.hatenastaff.com
業務パートの感想
実装した機能が本番環境で不具合なく動いているのを見てめちゃくちゃ感動した。しかも多数のユーザさんから肯定的に受け取られていて再び感動。エンジニアという生き物はこの瞬間のために生きているのではないか。
インターン期間内にリリースできたのは、メンターさんをはじめとするブクマチームの皆さんと、同じくブクマチームに配属された id:mds_boy さんのおかげだった。チームの皆さんにはリモートなのに常に反応をもらえるレベルで全力サポートしてもらえたし、mdsさんはコードを読むのも書くのも圧倒的に早く、全体的に引っ張っていってもらえた超ラッキーな立場だったと思う。実際Perlでかなり危険なコードを書いたりもした。
それでも、方々でメンターさんにめちゃくちゃ褒めていただいてとても嬉しかった。
とはいえ、今回はメンターさん頼り放題プランで、(リリースまでだいぶ短いのもあって)わからないことを聞きまくっていたが、実際の業務になるとそうもいかないはずで、その中でも自分がしっかり貢献できるイメージはあまり浮かばない。今のままでは実力が足りていないと思う。(インターンで社員並みの働きができる方が異常だと思うけど)
ちゃんとチームに貢献できるエンジニアになるために、そしてリリースできて気持ち良くなった経験をもう一度味わうために、これからも精進したい。
まとめ
講義も業務も最高!
なぜ自分がお金をもらう側なのか不安になるレベルで最高の体験だった。
あなたもはてなインターンで最高の夏を過ごしてください。
以下余談
始まり
インターンの応募課題はF12押せばいいだけで、自明だった。
「これ受からなかったら普通に夏休みは勉強漬けでいいか〜」と思って、はてなさん以外のインターンはどこも受けなかった。 はてな一筋!
というのも、はてなさんはインターンに激慣れしていて、サポートがはちゃめちゃに手厚いのを過去の体験記からひしひしと感じていたからで、本格的なインターンが初めての自分はここ以外考えられなかったからである。
ちなみに、はてなインターン2021の応募資格には「メモリ16GB以上のPCを用意できる」というのがあって、自分のは8GBなので、実はかなりハイレベルなダメもとだった。
面談
面談のメールをいただいたときは、8GBなのに時間をとってもらっていいのかと思っていたけど、残りの8GB分は気合と技術力でカバーするつもりで面談に臨んだ。
ものすごく緊張している自分にアイスブレークを投げてくださり、やってきたこと、やってみたいこと、過去の開発の失敗談など色々伝えることができて楽しかったし、かなりの手応えを感じた。
この時の面談のお相手はid:taraoさんだったとチーム配属後に知り、面談の時点でこんな BIG な人にマンツーマンであれだけ時間を割いてもらえるというあたりにインターンへの期待や本気度のようなものを再確認できた。
当落メールが来ない
迷惑メールに入ってました😵
当落メール来た!と思ったら、実はそのメールはリマインドで、先日ご連絡を差し上げたとか参加の可否が確認できていないとか書いていて、心臓が止まるかと思った。
リマインドも迷惑メールに入っていたら、Googleの全てを憎み戦うバーサーカーになっていたと思う。
ちなみに、過去に重要なメールがプロモーションのタブに入っていて破滅したこともある。プロモーションタブを消して全部受信トレイに来るようにしてもなおこういうことが起きるが、とりあえずプロモーションタブは消した方がいいと思う。
立つ鳥跡をめっちゃ濁す
最終日にはてな社サーバー上で動いているScrapboxに間違えてMackysonという名前のProjectを生やして、しかもなんか削除ができないという状態になった。
記念碑ということにした。