論文まとめ: Are You Sure You Want to Use MMAP in Your Database Management System?
研究室内に向けまとめたものの転載です.
一言でいうと
著者/所属機関
Andrew Crotty $^1$ , Viktor Leis $^2$ , Andrew Pavlo $^1$
$^1$ Carnegie Mellon University $^2$ University of Erlangen-Nuremberg
mmap(memory-mapped I/O)について
mmapはメモリに用いるアドレス空間を,I/Oデバイス(HDDやSSDはこれに含まれる)と共有して, I/Oデバイスに対するRead/Writeをメモリに対するRead/Writeと同一に見えるようにする仕組み.
「プログラマーのためのCPU入門」の7章が参考になると思います.
概要
- mmapを使えば,まるでファイル全体がメモリに乗っているように見える.
- これでバッファプールの実装が不要になったかのように思えたが,すぐには顕在化しない一貫性や性能への悪影響があった.
- 実際,最初mmapを採用していたDBMSも,後に自力でI/Oを管理するように舵を切っている.
Disk-based DBMSとページ管理
- 実際に積んでいるメモリのサイズより多くのデータを扱うlarger-than-memoryはDisk-based DBMSにおいて重要
- メモリよりも大きいデータを扱うために,二次記憶(HDDやSSD)とメモリ間でデータを出し入れしつつ頑張る.
- いわゆる"ページング"
- メモリが足りなければ,今乗っているページがevictされて,新しいページを読み込む
- ページの大きさは大抵の場合4KiB
- ちなみに,Linuxならめちゃくちゃデカい(1桁MiBぐらい)ページを確保できる("superpages")
- mmap無しの場合,ページの管理はシステムコール(read,write)経由で完全にDBMSが行う
- 一方,mmapを使えばページ管理の責務をOSに転嫁できる
- DBMSから見るとすべてのデータがメモリ上にあるように見える
- 当然,実装はものすごく楽になる
- 性能面からも,明示的システムコールがなくなる上に,OSのページキャッシュを使えるので早くなるように思われた
- 有名なDBMSも過去にmmapを使っていて,なんなら mmapのおかげで早い! と謳うものすらあった.
mmapについて
mmapを利用したときの流れ
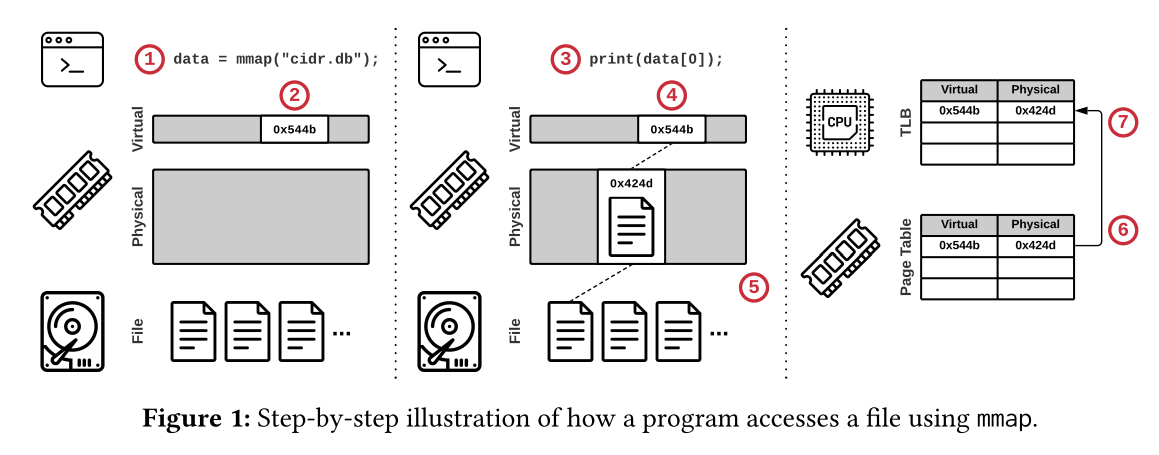
以下はmmapを使ったときの動き
別のページが要求されれば同様の手順を踏む
- ページフォールトが起きてページキャッシュがいっぱいな場合,OSはページをevictする
- evict時にはページテーブルとTLBの両方からアドレスの対応を消す
- evictを走らせるコアのTLBだけでなく,リモートのコアのTLBからも消さないといけない
- 現代のCPUには,よそのコアのTLBとの一貫性を保証する機能はないので,OSが割り込みで解決する
- これを"TLB shootdown"という
- これがヤバい!(実験結果を参照)
- これを"TLB shootdown"という
- 現代のCPUには,よそのコアのTLBとの一貫性を保証する機能はないので,OSが割り込みで解決する
ケーススタディ
MongoDB
- MongoDBは最初(納期に追われて)mmapを利用して作られたが,2つの問題に直面した
- 1つは一貫性を保証するための手続きが複雑になったこと(後で詳しく)
- もう1つは二次記憶にあるデータの圧縮ができないこと
- マッピングされているので,メモリ上のデータレイアウトが二次記憶のものと一致しなければならないことによる
- 圧縮すればI/Oの回数が減る上に,容量も削減できるのに……
- 2019年に完全にmmapを使わなくなった
- ただし,2020年に限定的な用途のためにmmapが復活している
InfluxDB
- 数GBの時点で(恐らくpage evictionの影響で)I/Oがスパイクすることが判明
- しかもコンテナ環境などで使えないことも分かった
- 2020年にコアを書き換えてmmapは消滅
SingleStore
その他
- Google製のLevelDBのreadのボトルネックがmmapのせいだったので,FacebookがforkしてRocksDBを作った
- TileDBの論文では,SSDにおいてmmapがreadシステムコールより高コストなことが示されている
- 「SSDはアクセスがミリ秒未満だから」とのこと
- ScyllaDBはI/Oの代替を色々と検討した結果,mmapではpage eviction戦略もI/O操作のスケジューリングも細かくできないので使わなかった
- その他,色々……
mmapで起きる問題
問題1: Transactional Safety
- OSはいつでもdirty pageをフラッシュしていい
- もちろん,コミットされていないトランザクションの途中でも……
- これの対策は3つ
- OS copy-on-write
- user space copy-on-write
- shadow paging
OS copy-on-write
- 昔のMongoDBが使っていた
- データベースファイルのコピーを2つ用意する手法
- 1つはプライマリ,もう1つはステージング用
- ステージング用のファイルを使ってトランザクションによる更新を処理し,それをプライマリに反映という手続き
- ステージング用のファイルはcopy-on-write方式でページを管理する
- この手法は2つの問題がある
- 1つは並行するトランザクションの読み取り時にコミットされた最新のデータがプライマリに反映されていることを保証しなければならないこと
- このために更新をペンディングしなければならない
- もう1つはcopy-on-writeといえども,更新の度にステージング用コピーの容量が増えていくこと
- 最終的にdbファイル2つ持ってるみたいなことに
mremapという命令で一応解消できるが,mremapの前後で更新の喪失を防ぐためにはやはりコストがかかる
User Space Copy-on-Write
- SQLite,MonetDB,RavenDBが使っている
- User spaceでバッファを用意して,そこに変更を積んでいき,DBMS管理で適宜mmapされたメモリに転送する手法
- (個人的には,これ普通にバッファ管理してるだけじゃない?と思います)
shadow paging
- LMDBが使っている
- DBファイルのコピーを2つ用意し,片方をプライマリ,もう片方をshadowとする手法
- 書き込み時には,必要なページをプライマリからshadowへコピーして,shadowへ変更を適用
- その後
msync命令で二次記憶へ転送し,shadowが新しいプライマリとしてふるまう- もとのプライマリはshadowとして振る舞う
- 簡単そうに見えるけど,partial writeを見ないことを保証しないといけないのが鬼門になる
- LMDBではsingle writerで解決
- (絶対性能出ないだろこれ)
- LMDBではsingle writerで解決
問題2: I/O Stalls
- バッファプールを使う場合,非同期I/Oを使って,クエリ処理中に必要なページを読んでおくテクがある
- B+木のスキャンが典型的なユースケース
- しかし,mmapは非同期読み取りをサポートしていない
- I/Oのコストを隠蔽できない!
- evictのコントロールができないので,いかなるページへのアクセスもページフォールトを起こしてI/Oで詰まる可能性がある
- システムコールを駆使すれば一応解決は可能
- ①
mlockを使って特定ページのevictを防ぐ- ただし,
mlockしすぎるとメモリが足りなくなる - unlockに気をつける必要もある
- ただし,
- ②
mapadviseを使って,アクセスパターンのヒントをOSに渡し,プリフェッチを狙う- OSはヒントを無視していいので意味ないかも
- 間違ったヒントを渡すと悲惨(実験結果を参照)
- ③プリフェッチ用のスレッドを走らせる
- ①
- これらの解決策でどうにかはなるけど,めちゃくちゃ複雑になる
- mmapを使う目的は取り扱いの簡単さだったはずなのに……
問題3: エラーハンドリング
- データが壊れてないことを保証するのもDBMSの役割
- よってデータの破損を検知するためにチェックサムを取るDBがある
- メモリ安全性が弱い言語を使ったとき,ポインタまわりのエラーでメモリに乗っているページの中身が破損する場合がある
- バッファプールを使えば永続化する前に検知して止められるが,mmapを使うと破損したデータが自動的に永続化される
- mmapが絡んだメモリは
SIGBUSを引き起こす可能性があり,これはシグナルハンドラ経由で解決しなければならない- バッファプールなら単一モジュールでI/Oエラーを捌けるのに……
問題4: パフォーマンス
- バッファプールなら単一モジュールでI/Oエラーを捌けるのに……
- 一貫性などの問題は実装次第でなんとかなるけど,パフォーマンスは手の付けようがない
- そもそもmmapの利点として考えられていたのは以下の3つ
- read/writeなどのシステムコールが少ない
- OSのpage cacheに乗っているページへのポインタを返すことができ,バッファへの余計なコピーが不要
- データをuser spaceにコピーしなくていいので省メモリ
- 以上の点はI/Oデバイスの帯域が広がるほど効くはず
- しかし,page evictionのせいでスケールしないことが分かった
- ボトルネックは以下の3つ
- ページテーブルの同期による競合
- シングルスレッドで走るpage eviction
- TLB shootdown
実験
実験設定
- 使用機器は以下
- read-onlyワークロード
- 一貫性のためのコピーがいらないので,mmapに有利
- ランダムリードとシーケンシャルスキャンでそれぞれ検証
- ベースラインはfioというI/O用ベンチマークツールとDirect I/Oを合わせたらしい
- よくわかりません
- DBのサイズは2TB
実験結果
ランダムリード
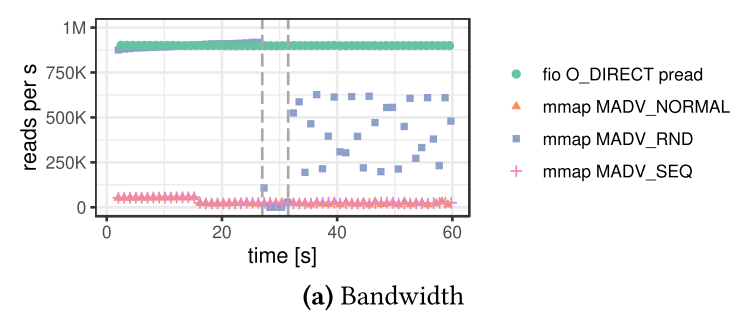
- Figure 2aは100スレッドでランダムリードしたときのスループット
- MADV_NORMALは特に特別なことをしないパターン(アクセスパターンのヒントを与えないのと同じ)
- 他は名前の通り
- ベースラインは900k reads
- NVMe SSDのレイテンシ的に,これは理論値
- mmapの方はおしまい
- ランダムリードのヒントを渡したものは27秒までは耐えている
- 5秒ぐらい地を這ったのち,fioの半分ぐらいの性能に
- 27秒辺りでページキャッシュが埋まり切った
- 間違ったヒントを渡したものは悲惨な結果に
- ランダムリードのヒントを渡したものは27秒までは耐えている
- ページキャッシュが小さい(100GB << 2TB)ので95%のアクセスがページフォールトを起こしている
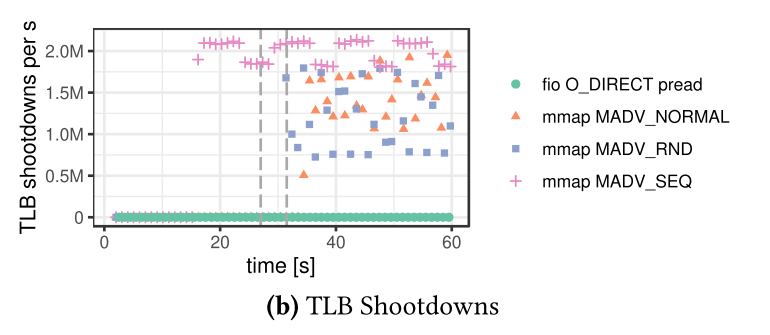
- ランダムリード中のTLB shootdownの数を
/proc/interruptを使って計測- ご覧の有り様
シーケンシャルスキャン
- ご覧の有り様
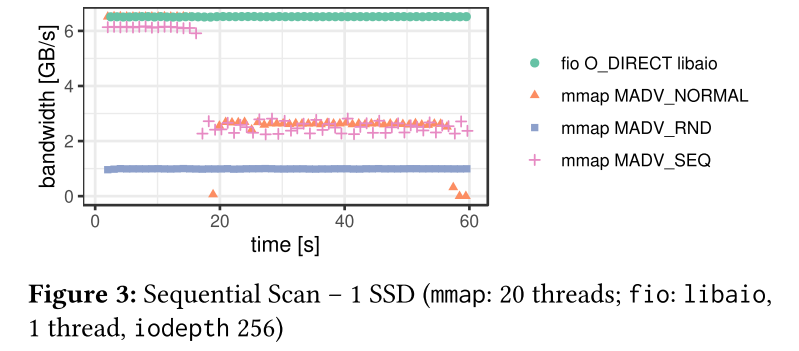
- Figure 3は1つのSSDを使ってシーケンシャルスキャンをした時のスループット
- fioは帯域を使い切れている
- mmapの方はおしまい
- ランダムリード同様,キャッシュが埋まるまでは耐えるが急に沈む
- 間違ったヒントを渡したらやはり悲惨
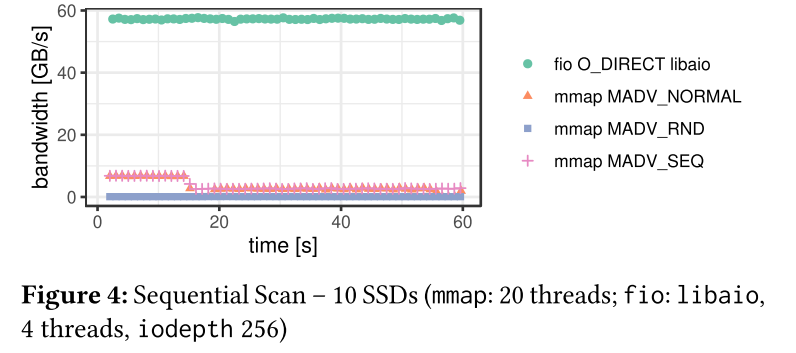
- Figure 4は同様の実験をRAID-0構成の10個のSSDを使ってシーケンシャルスキャンをした時のスループット
- fioはざっくり10倍ぐらいに(RAID-0なので)
- mmapはどれもSSD 1台構成の時と同じ性能になっている
- つまり,mmapはSSDが1台で,ページキャッシュが埋まっていない間だけfioに匹敵する
- 裏を返せば,それ以外は……
まとめ
mmapを使わない方がいい人
mmapを使ってもいいかも?な人
- 走らせたいワークロードがメモリに乗る人
- (ならインメモリDBでいいじゃん)
- データの一貫性とか技術的負債とか考えられないぐらい納期が迫っている人
- そんな奴はいない
コメント
- LMDBへの熱いdisを感じてイイですね.
- 2019年にIEEEが出してる雑誌のLMDBの紹介記事によると,LMDBは世界で最も高速かつ効率的で,最も安全な組み込みデータストアの1つらしいです. そうなんだ.